微信聊天克隆数字分身 WeClone让记忆中的TA永生
阅读:634 新闻动态
微信聊天记录克隆数字分身:WeClone项目让记忆中的TA在数字世界永生
你的微信里有没有一个对话窗?它很久都没有弹出新消息,但你却常常在深夜里点开反反复复地翻着那些旧日的对话。如果现在,你可以用这些聊天记录克隆出对方的"数字分身",保存下TA说话的语气、风格、独特的口头禅,甚至还能给你发来语音,你会怎么选择?
最近,GitHub上新开源了一个名为WeClone的项目——让你记忆里的那个TA在数字世界里永生,已不再是不可能实现的幻想。
项目概述
WeClone通过个人微信聊天记录对大语言模型(LLM)进行微调,打造个性化的数字分身。它提供从文本生成到语音克隆、从训练到部署的全链路解决方案,让数字分身不仅能够模仿TA的说话方式,还能还原TA的声音特征。
除了留住记忆里的TA,你也可以创造自己的数字分身。想象一下,和自己聊天会是什么样的体验?你会喜欢和自己对话吗?
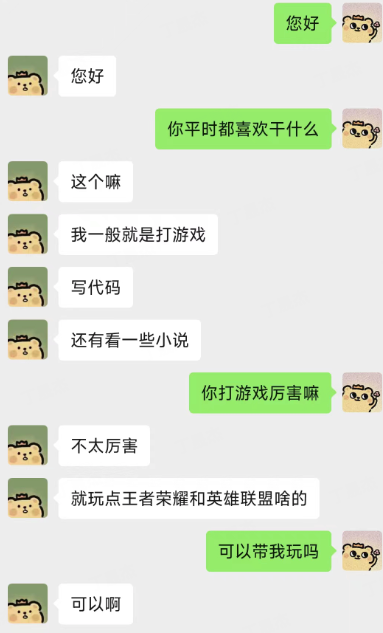

数字人技术的可玩性确实很高,一经推出就在国内外引起了广泛关注。许多网友纷纷脑洞大开,提出了各种有趣的应用场景。
项目地址:https://github.com/xming521/weclone
核心功能
1. 使用微信聊天记录微调LLM
WeClone支持导出微信聊天记录,并进行格式化处理成问答格式,用于模型微调。在模型微调方面:
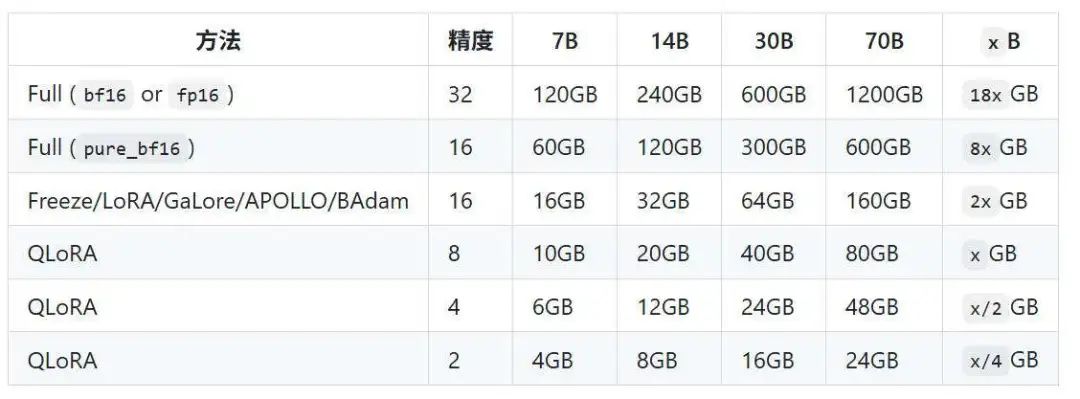
- 基于LoRA支持对主流0.5B-7B规模模型进行低资源微调
- 支持ChatGLM3-6B、Qwen2.5-7B等模型
- 有效捕捉用户的语言习惯和表达方式
- 训练需要约16GB显存,显存需求可控
2. 语音克隆技术
项目配套子模块WeClone-audio基于轻量级Tacotron或WavLM模型:
- 仅需0.5B参数模型和5秒语音样本
- 克隆出相似度高达95%的声音
- 进一步增强数字分身的真实感
3. 多平台部署
通过AstrBot框架,可将数字分身部署到:
- 微信
- Telegram
- 企业微信
- 飞书
一行命令即可快速启动,与数字分身实时对话。
应用场景
- 个人助理定制:在你忙碌时,数字分身可以代替你回复消息,处理日常事务
- 内容创作:快速产出特定风格的个性化文本内容,帮助运营多个风格一致的小号
- 数字永生:创建自己或者他人的数字分身,实现记忆的永久保存
技术实现
WeClone的数字分身全链路核心模块包括三部分:
-
数据导出与预处理
- 将微信导出的CSV/SQLite文件转为标准JSON
- 文本清洗去除噪声和敏感信息
- 分割对话信息并保留时间戳
-
模型微调
- 使用ChatGLM3-6B为基础模型
- 基于LoRA框架进行SFT微调
- 关键技术亮点:
- 使用低秩适配器减少可训练参数
- 支持单机/分布式训练
-
模型部署
- 使用FastAPI/Flask打包微调后的模型
- 支持GPU/CPU混合部署
- 多平台登录支持
- 自定义参数功能
安装与使用教程
环境搭建
建议使用uv(Python环境管理器):
git clone https://github.com/xming521/WeClone.git
cd WeClone
uv venv .venv --python=3.9
source .venv/bin/activate
uv pip install --group main -e .注意:训练和推理相关配置统一在settings.json文件中。
数据准备
- 使用PyWxDump提取微信聊天记录
- 解密数据库后导出CSV格式
- 将导出的CSV文件夹放在
./data/csv目录下
数据预处理
项目默认会去除:
- 手机号
- 身份证号
- 邮箱
- 网址
还提供了禁用词词库blocked_words,可自行添加需要过滤的词句。
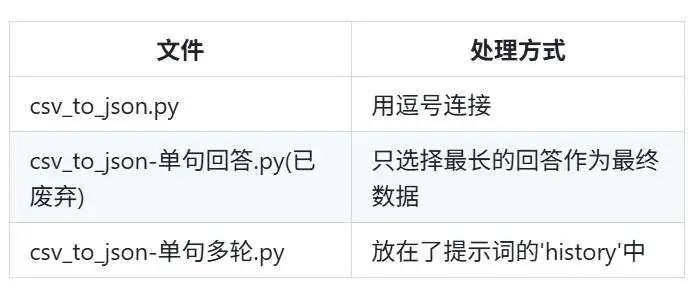
执行./make_dataset/csv_to_json.py脚本处理数据。
对于连续回答多句的情况,提供三种处理方式:
模型下载
推荐从Hugging Face下载ChatGLM3模型。如遇下载问题,可使用魔搭社区:
export USE_MODELSCOPE_HUB=1 # Windows使用`set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git注意:魔搭社区的modeling_chatglm.py文件需要更换为Hugging Face版本。
训练配置
- (可选)修改
settings.json选择本地下载的其他模型 - 调整
per_device_train_batch_size和gradient_accumulation_steps控制显存占用 - 根据数据集调整
num_train_epochs、lora_rank、lora_dropout等参数
单卡训练
python src/train_sft.py多卡训练
uv pip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.py推理测试
-
浏览器demo:
python ./src/web_demo.py -
API接口:
python ./src/api_service.py -
常见问题测试:
python ./src/test_model.py
部署到聊天机器人
AstrBot方案
AstrBot是易上手的多平台LLM聊天机器人及开发框架。
部署步骤:
- 部署AstrBot
- 在AstrBot中部署消息平台
- 启动API服务:
python ./src/api_service.py - 在AstrBot中新增OpenAI类型服务提供商
- 关闭默认工具:
/tool off reminder - 根据微调时使用的
default_system设置系统提示词
通过WeClone项目,我们不仅能够保存珍贵的记忆,还能探索人与AI交互的无限可能。这项技术正在重新定义我们与数字世界互动的方式。