AI生成多人游戏Multiverse开创性世界模型突破
阅读:619 新闻动态
今天,AI生成技术再次迎来一次开创性的变革——来自以色列的Enigma Labs团队推出了全球首款AI生成的多人游戏Multiverse!以下是关于这一突破性技术的详细介绍。
Multiverse:低成本高效率的开发奇迹
不得不提的是,整个游戏的开发仅花费了1500美元,就完成了数据收集、标记、训练和模型研究等所有工作。更令人惊叹的是,这款游戏可以在个人PC端轻松运行。
游戏效果展示
我们先一起来看看游戏的实际效果。
AI生成的下一个模态:世界模型
AI生成技术已经走过了很长的路,从文本、音频、图像,再到视频。那么,视频之后是什么?一个广受认同的答案是——世界模型将是AI生成的下一个主要“模态”。
世界模型可以模拟虚拟(或物理)世界如何随着代理(例如玩家)的行为而演变。而Multiverse的出现标志着AI生成的世界模型不再只是单人游戏,而是能够实现两个AI大脑在同一个连续、统一的世界里遵循同样的物理规律作出反应。这代表了AI生成世界模型发展的一大步。
一经推出,Multiverse便收获了大量好评。
开源项目与资源
Enigma Labs还开源了Multiverse的所有内容,包括代码、数据、权重、架构和研究。以下是一些重要资源的链接:
- Github: https://github.com/EnigmaLabsAI/multiverse
- Hugging Face: https://huggingface.co/Enigma-AI
- 项目博客: https://enigma-labs.io/blog
接下来,让我们深入探索Multiverse的技术架构,看看他们是如何实现这一突破的。
Multiverse的架构探究
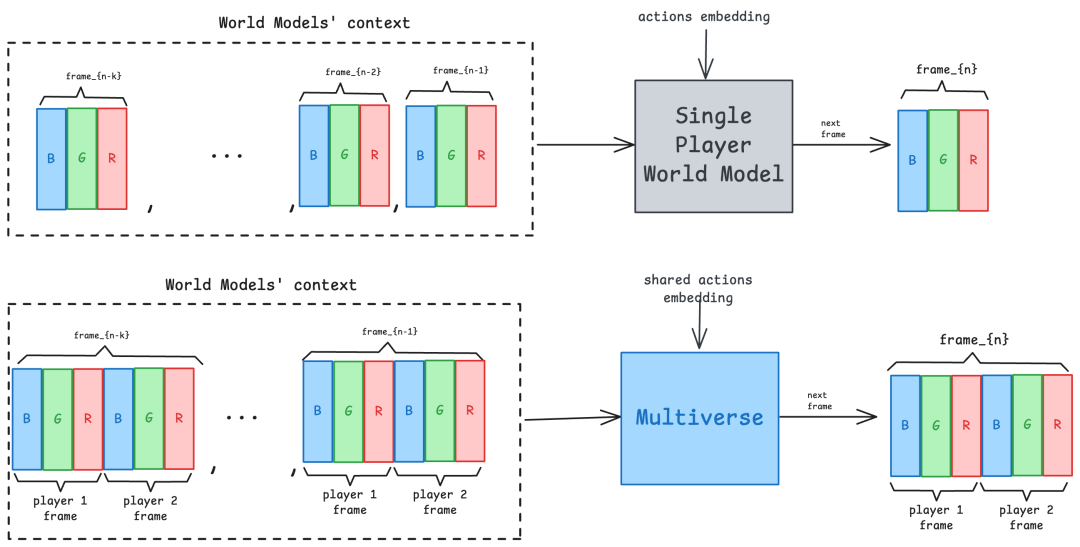
单人游戏架构回顾
在理解其多人游戏架构之前,我们先回顾一下单人游戏架构。
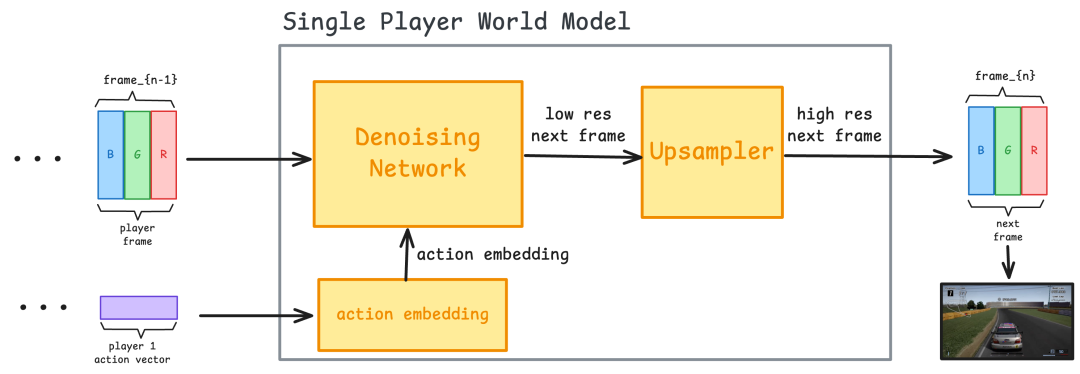
单人游戏架构主要由三个部分组成:
- 动作嵌入器:将玩家的操作转化为嵌入向量。
- 去噪网络:依据之前的帧和动作嵌入生成新的帧。
- 上采样器(可选):对世界模型生成的低分辨率帧进行处理,提升输出的细节和分辨率。
Multiverse的多人游戏架构
基于这些基础组件,Multiverse在多人游戏架构上进行了创新。它保留了核心模块,但拆解了结构,重新连接了输入和输出,并重新设计了训练过程,从而实现真正的合作游戏。
- 动作嵌入器:接收两名玩家的动作,并输出一个统一的嵌入向量。
- 去噪网络:根据两名玩家之前的帧和动作嵌入,同时生成他们各自的帧。
- 上采样器:与单人游戏版本类似,但会同时计算两名玩家的上采样版本。
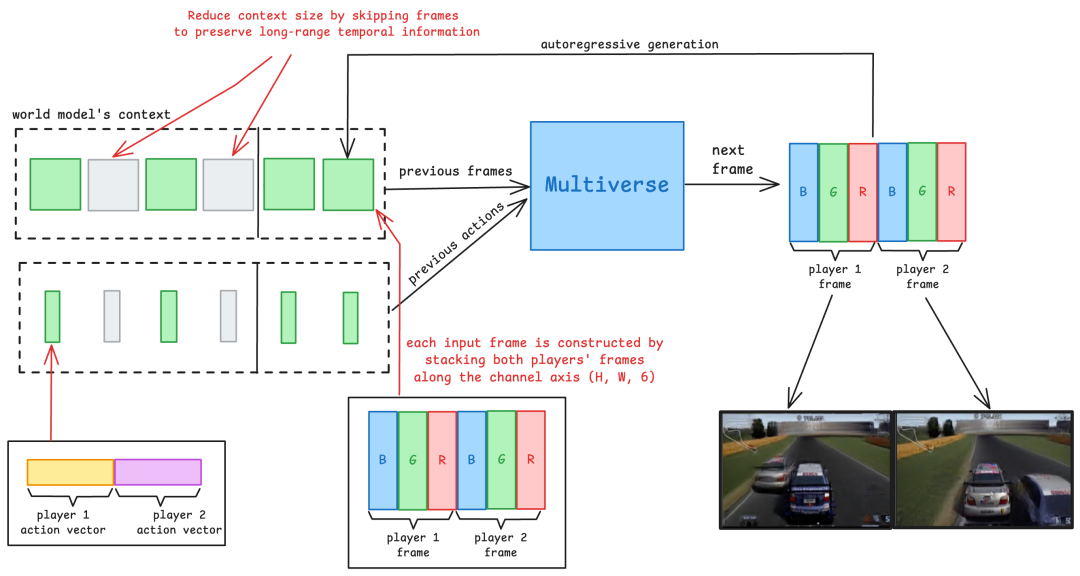
为了创建多人游戏体验,模型需要考虑两个玩家之前的帧和动作,并输出每个玩家的预测帧。关键在于,这两个输出不仅需要各自看起来不错,还需要在内部彼此一致。这正是难点所在,因为多人游戏依赖于共享的世界状态。
解决一致性问题
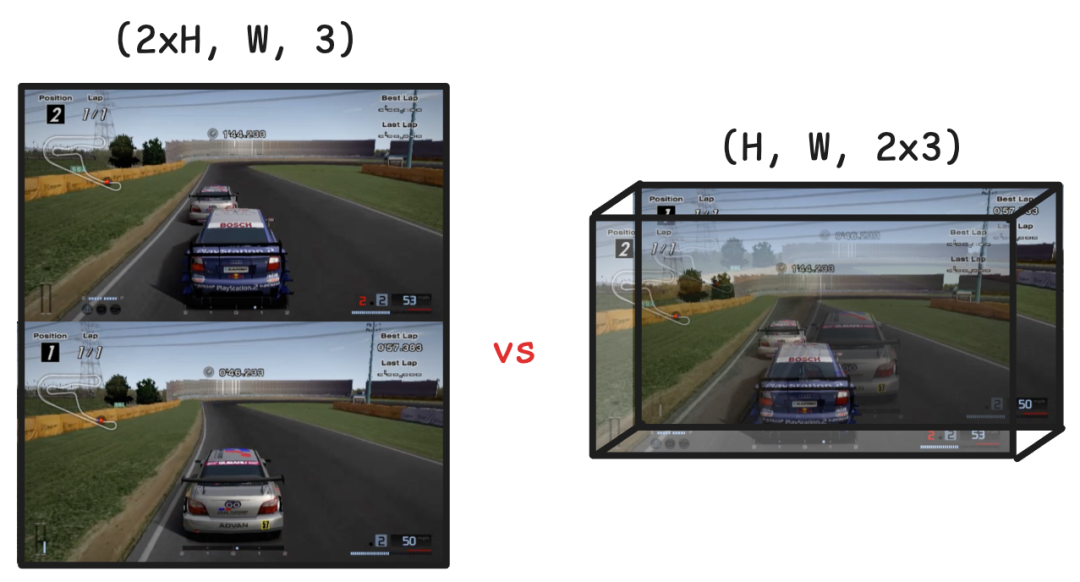
Multiverse提出的解决方法是:将两个玩家视图拼接成一个图像,将它们的输入混合到一个联合动作向量中,并将整个过程视为一个统一的场景。
这引出了另一个问题——将两个玩家视图合并为模型可以处理的单个输入的最佳方法是什么?有两个可供选择的方法:
- 垂直堆叠:就像经典的分屏游戏一样。
- 沿通道轴堆叠:将两个帧视为一个具有两倍颜色通道的图像。
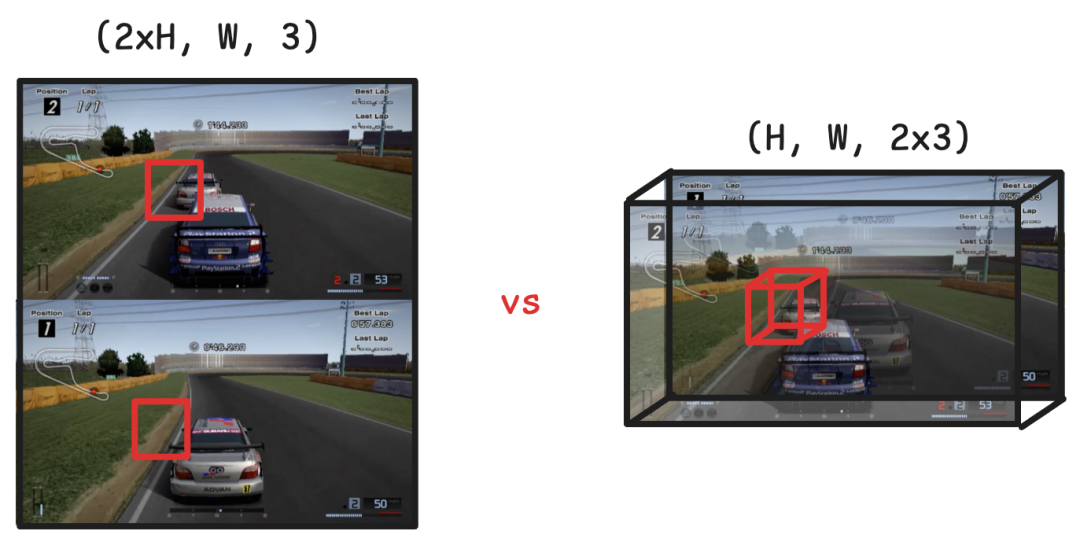
Multiverse选择了第二种方法,即沿通道轴堆叠。因为Multiverse使用的扩散模型是一个U-Net,主要由卷积层和反卷积层组成,所以第一层只处理附近的像素。如果垂直堆叠两个帧,则帧直到中间层才会一起处理。这会降低模型在帧之间生成一致结构的能力。
另一方面,当在通道轴上堆叠帧时,两个玩家的视图在网络的每一层上都一起处理。
高效上下文扩展:车辆运动学与相对运动建模
为了准确预测下一帧,模型需要接收玩家的动作(如转向输入),并需要足够的帧来计算两辆车相对于道路和彼此的速度。
Enigma Labs在研究中发现,8帧(30 fps)允许模型学习车辆运动学,例如加速、制动和转向。但是两辆车的相对运动比在道路上的相对运动要慢得多。例如,车辆以约100公里/小时的速度行驶,而超车的相对速度仅为约5公里/小时。
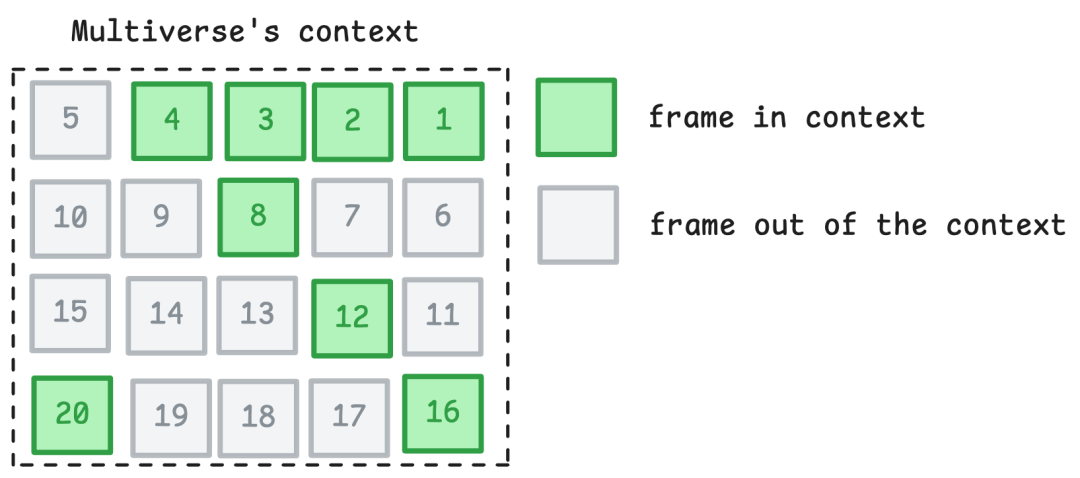
为了捕捉这种相对运动,Multiverse将上下文大小增加近三倍。但这将使模型对于实时游戏来说太慢,增加其内存使用量,并使训练速度变慢。为了保持上下文大小但允许更大的时间信息,Multiverse为模型提供了前面帧和动作的稀疏采样。具体来说,给模型提供最新的4帧,然后为接下来的4帧提供每4帧。上下文中最早的帧是20帧,过去0.666秒,足以捕捉车辆的相对运动。作为额外的好处,这使模型能够更好地捕捉与道路相比的速度和加速度,从而使驾驶动态更加出色。
多人游戏训练
为了学习驾驶和多人游戏交互,模型需要对此类交互进行训练。世界模型中的步行、驾驶和其他常见任务需要较小的预测范围,例如未来0.25秒。然而,多人游戏交互需要更长的时间。在0.25秒内,玩家之间的相对运动几乎可以忽略不计。
为了训练多人游戏世界模型,模型需要更长的预测范围。因此,Multiverse团队训练模型预测在未来15秒内执行自回归预测(以30 fps的速度)。为了让模型能够执行如此长的预测,他们采用了课程学习,并将训练期间的预测范围从0.25秒增加到15秒。这允许在初始训练阶段进行高效训练,此时模型正在学习汽车和赛道几何等低级特征。并在学会生成连贯帧和建模车辆运动学后,根据玩家行为等高级概念对其进行训练。
在增加预测范围后,模型的对象持久性和帧之间的一致性显著提高。
高效的长距离训练
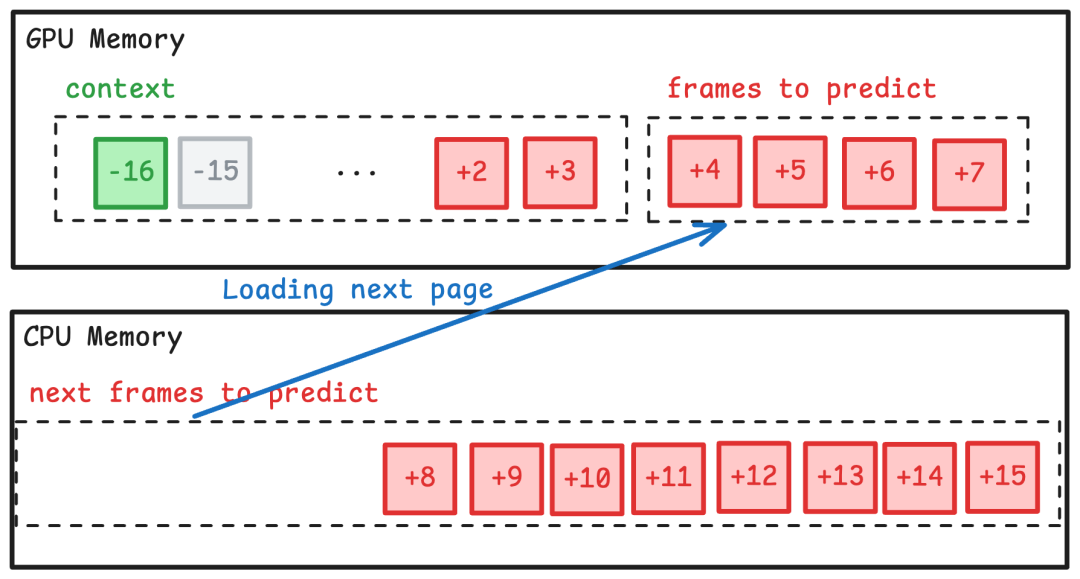
训练超过100帧的模型会带来VRAM挑战。因为在大批量中,将帧加载到GPU内存中进行自回归预测变得不可行。为了解决这种内存受限的问题,Multiverse在页面中执行自回归预测。
在训练开始时,模型加载第一批并对其执行预测。
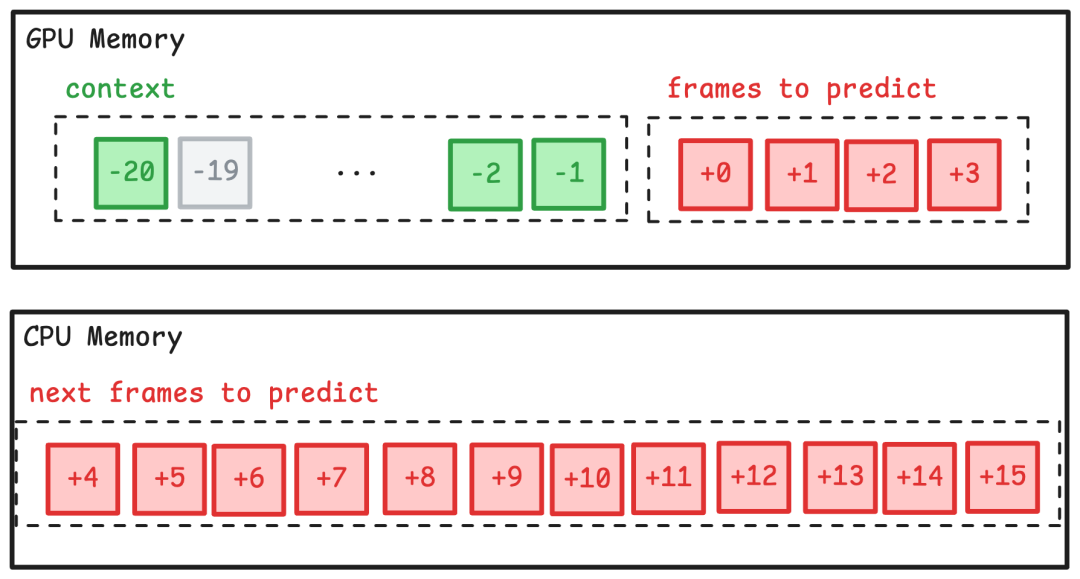
然后加载下一页并丢弃上下文窗口之外的框架。
Gran Turismo数据集
Enigma Labs训练Multiverse的数据集来自索尼的游戏《Gran Turismo 4》(GT赛车4)。
设置和游戏修改
他们使用了一个简单的测试案例:以第三人称视角在Tsukuba Circuit上进行1对1比赛。Tsukuba Circuit是一条短而简单的赛道,非常适合训练。但问题是:Gran Turismo 4不允许以全屏1对1的方式运行Tsukuba。游戏仅将其作为1-v-5或分屏头对头提供。为了获得模型需要的设置,团队对游戏进行了逆向工程和修改,以真正的1对1模式启动Tsukuba。
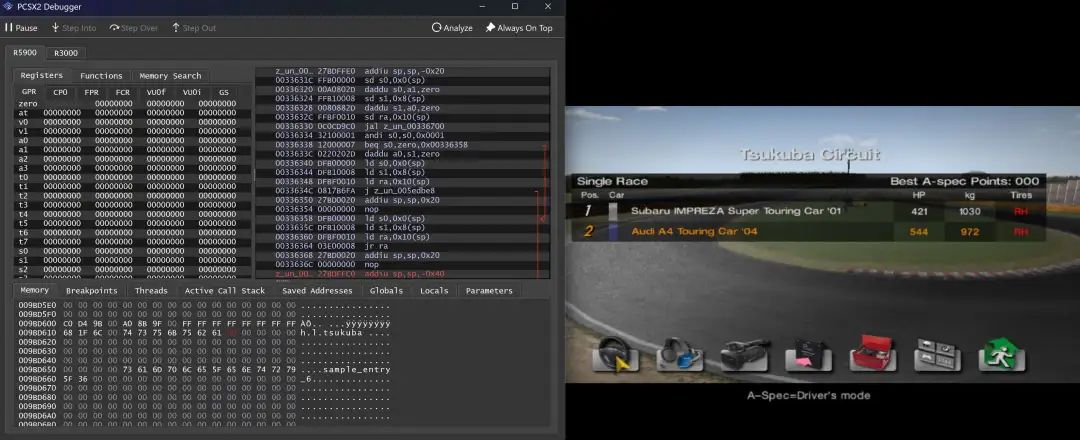
数据采集
为了收集两名玩家的第三人称视频数据,Enigma Labs团队利用了游戏内回放系统——每场比赛重播两次,并从每个玩家的角度进行录制。然后,他们同步了两个录像以匹配最初的双人比赛,将它们合并成两个玩家同时一起玩的单个视频。
那么在其中一名玩家是游戏机器人而不是人类的情况下,他们是如何捕获数据集的按键?幸运的是,游戏在屏幕上显示了足够的HUD元素(如油门、刹车和转向指示器),以准确重建达到每种状态所需的控制输入。
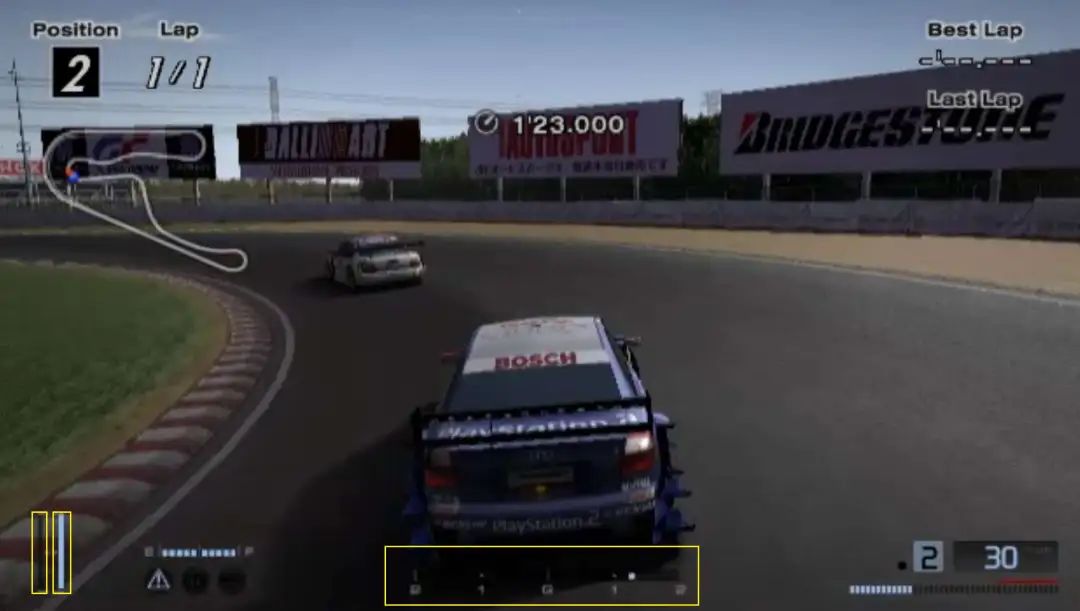
使用计算机视觉,他们逐帧提取这些条形,并解码它们背后的控制输入。从而可以直接从视频中重建完整的按键集,在没有任何直接输入记录的情况下构建整个数据集。
自动数据生成
乍一看,Enigma Labs团队似乎不得不坐下来手动玩几个小时的游戏,每场比赛都录制两次重播。虽然他们使用的开源数据集的一部分确实来自手动游戏,但他们发现了一种更具可扩展性的方法:B-Spec模式。这种Gran Turismo模式围绕着